- Roles
- Technical Writer, Software Developer, UI Designer
- Skills
- Perl, IPF
It’s 1996, the first year as a regular employee at IBM. During my time as an intern, I chose to learn Perl. It’s a forgiving language originally designed to manipulate text. It’s the perfect companion to an IBM technical writer, whose document source has always been some type of text file, whether it be script, troff, BookMaster, IPF, SGML, and currently DITA and Markdown.
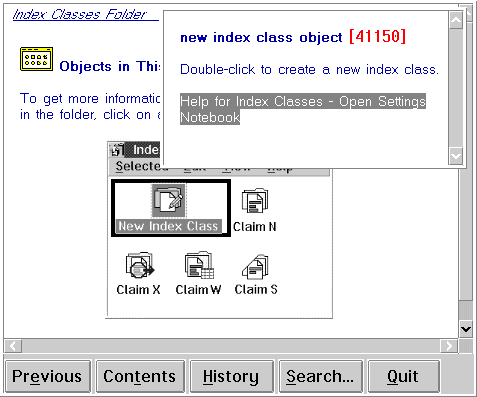
My first project was to make the online help more visually appealing. IBM OS/2 help is authored in the IPF language, which—like early HTML—mixes presentation with content. Once a help author starts writing, it’s nontrivial to change the presentation behavior if user feedback suggests it.
I therefore used Perl to separate content from presentation. It’s a simple concept, really, like a mail merge. To avoid repetition and wasted time, identify parts that are functionally similar and separate things that change from things that don’t change.
I migrated the content to records in a data file and put the presentation code in a separate script. The script pulled in the data to produce the composite OS/2 IPF source and build it. I was able to easily alter the presentation in the script while leaving the data untouched.
An added benefit was that I was able to deliver various versions of the help with little effort: the graphic intensive US-only version, an international version without graphics, and a version that displayed resource IDs for reviewers.